How does useId() work internally in React?
useId() hook works internally, it must be fun
since I’ve never used it before actually.
Problem Statement
The official doc for useId() has a nice explanation, here I’ll just try to explain in my own words.
Let’s say we have to use <label> for a checkbox <input type="checkbox">,
in order to pair them up, we need to use the attribute
for,
which is htmlFor in React realm.
jsx
jsx
Above usage of htmlFor pairs them up so clicking on the label works the same as
clicking on the checkbox.
But the id is solely to do paring, we actually don’t want to spend time thinking about a good semantic id, it works fine as long as it is unique. Since the id needs to be globally unique, easily we can create a global id generator by simply increamenting an integer, this is actually what I was always doing in my work.
jsx
jsx
It seems to work! And it does work, but there is still a caveat - the id changes every time Component is rendered, this means there will definitely be unecessary DOM update.
We can change it to a hook that uses useState()
useRef() doesn't support lazy initializer
so simply use useState() here (we can still use
useRef()though)return id;}
useRef() doesn't support lazy initializer
so simply use useState() here (we can still use
useRef()though)return id;}
It should theoretically work. But there is still another issue related to hydration.
Reacall we’ve explained What is Progressive Hydration and how does it work internally in React, let’s say there are multiple Suspenses(Suspense1, Suspense2) rendering fallbacks on server because of thrown Promises(Promise1, Promise2), and in the children of both Suspenses, useId() is used.
Problem is once useId() is called on server, we are not 100% sure that chunk with smaller id will arrive on client earlier because of network, so a chunk with larger id might come first then triggers client rendering and useId() on client generates smaller id, thus a mismatch occurs and then hydration fails.
As the official doc says,
This is very difficult to guarantee with an incrementing counter because the order in which the client components are hydrated may not match the order in which the server HTML was emitted
Solution
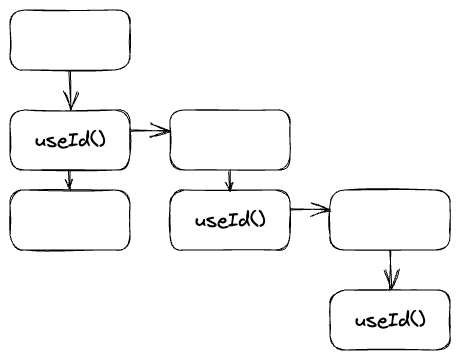
Look at above diagram, for multiple calls of useId() on a tree structure, we want to make sure that, they generate same unique ids no matter what the calling order of them are.
It seems that the only(?) approach would be generating ids based on their position on the tree, position is intrinsically unique and stable.
Well, I couldn’t come up with such approach by myself. With above explanation, the original PR looks more reasonable.
How does useId() work internally?
The PR actually explains pretty well, here let’s dive into the source code. After looking the source code of so many hooks (useEffectEvent(), useDeferredValue(), useImperativeHandle(), useRef(), useLayoutEffect()), it feels instinct to search in ReactFiberHooks.js, and it’s there.
mountId()
This is when useId() is called for initial render.
This function is called in reconciling on each fiber
So localIdCounter starts from 0 for each fiber
// This should be called immediately after every renderWithHooks call.// Conceptually, it's part of the return value of renderWithHooks; it's only a// separate function to avoid using an array tuple.const didRenderIdHook = localIdCounter !== 0;localIdCounter = 0;-----------------return didRenderIdHook;}function mountId(): string {const hook = mountWorkInProgressHook();const root = ((getWorkInProgressRoot(): any): FiberRoot);// TODO: In Fizz, id generation is specific to each server config. Maybe we// should do this in Fiber, too? Deferring this decision for now because// there's no other place to store the prefix except for an internal field on// the public createRoot object, which the fiber tree does not currently have// a reference to.const identifierPrefix = root.identifierPrefix;let id;if (getIsHydrating()) {const treeId = getTreeId();--------------------------// Use a captial R prefix for server-generated ids.id = ":" + identifierPrefix + "R" + treeId;// Unless this is the first id at this level, append a number at the end// that represents the position of this useId hook among all the useId// hooks for this fiber.const localId = localIdCounter++;if (localId > 0) {id += "H" + localId.toString(32);}id += ":";} else {// Use a lowercase r prefix for client-generated ids.const globalClientId = globalClientIdCounter++;If not hydrating, useId() falls back to a global counter
id = ":" + identifierPrefix + "r" + globalClientId.toString(32) + ":";}hook.memoizedState = id;return id;}
This function is called in reconciling on each fiber
So localIdCounter starts from 0 for each fiber
// This should be called immediately after every renderWithHooks call.// Conceptually, it's part of the return value of renderWithHooks; it's only a// separate function to avoid using an array tuple.const didRenderIdHook = localIdCounter !== 0;localIdCounter = 0;-----------------return didRenderIdHook;}function mountId(): string {const hook = mountWorkInProgressHook();const root = ((getWorkInProgressRoot(): any): FiberRoot);// TODO: In Fizz, id generation is specific to each server config. Maybe we// should do this in Fiber, too? Deferring this decision for now because// there's no other place to store the prefix except for an internal field on// the public createRoot object, which the fiber tree does not currently have// a reference to.const identifierPrefix = root.identifierPrefix;let id;if (getIsHydrating()) {const treeId = getTreeId();--------------------------// Use a captial R prefix for server-generated ids.id = ":" + identifierPrefix + "R" + treeId;// Unless this is the first id at this level, append a number at the end// that represents the position of this useId hook among all the useId// hooks for this fiber.const localId = localIdCounter++;if (localId > 0) {id += "H" + localId.toString(32);}id += ":";} else {// Use a lowercase r prefix for client-generated ids.const globalClientId = globalClientIdCounter++;If not hydrating, useId() falls back to a global counter
id = ":" + identifierPrefix + "r" + globalClientId.toString(32) + ":";}hook.memoizedState = id;return id;}
The logic is different based on getIsHydrating() - whether it is in hydration or not, we can see that
- it falls back to incrementing counter if not in hydration - same as what we did.
getTreeId()seems to generate the id- there might be multiple calls of
useId()in one component, they are differentiated by a postfix of their call order. inside of a component, the order is always stable so this works. - id is set in
memoizedStateof the hook, meaning it is kind of a state hook or useRef() hook, similar to what we did withsetState().
updateId()
For re-render, we can see from code below that, it simply get the stored id.
js
js
getTreeId() generates id from stacked tree structure info
js
js
treeContextId is a number, it is converted to 32-based string, concatenating overflow.
It isn’t obvious what it does, we need to first figure out treeContextId and treeContextOverflow.
pushTreeId() stacks tree structure info
This info is only pushed for children, not single child
// Check if this child belongs to a list of muliple children in// its parent.//// In a true multi-threaded implementation, we would render children on// parallel threads. This would represent the beginning of a new render// thread for this subtree.//// We only use this for id generation during hydration, which is why the// logic is located in this special branch.const slotIndex = workInProgress.index;const numberOfForks = getForksAtLevel(workInProgress);pushTreeId(workInProgress, numberOfForks, slotIndex);----------------------------------------------------}}}export function isForkedChild(workInProgress: Fiber): boolean {warnIfNotHydrating();return (workInProgress.flags & Forked) !== NoFlags;------}function placeChild(As mentioned in re-rendering,
placeChild()is to insert a new childOnly used for list of children. For single child,
placeSingleChild()is used.newFiber: Fiber,lastPlacedIndex: number,newIndex: number,): number {newFiber.index = newIndex;if (!shouldTrackSideEffects) {// During hydration, the useId algorithm needs to know which fibers are// part of a list of children (arrays, iterators).newFiber.flags |= Forked;------------------------return lastPlacedIndex;}...}
This info is only pushed for children, not single child
// Check if this child belongs to a list of muliple children in// its parent.//// In a true multi-threaded implementation, we would render children on// parallel threads. This would represent the beginning of a new render// thread for this subtree.//// We only use this for id generation during hydration, which is why the// logic is located in this special branch.const slotIndex = workInProgress.index;const numberOfForks = getForksAtLevel(workInProgress);pushTreeId(workInProgress, numberOfForks, slotIndex);----------------------------------------------------}}}export function isForkedChild(workInProgress: Fiber): boolean {warnIfNotHydrating();return (workInProgress.flags & Forked) !== NoFlags;------}function placeChild(As mentioned in re-rendering,
placeChild()is to insert a new childOnly used for list of children. For single child,
placeSingleChild()is used.newFiber: Fiber,lastPlacedIndex: number,newIndex: number,): number {newFiber.index = newIndex;if (!shouldTrackSideEffects) {// During hydration, the useId algorithm needs to know which fibers are// part of a list of children (arrays, iterators).newFiber.flags |= Forked;------------------------return lastPlacedIndex;}...}
pushTreeId() is also called in pushMaterializedTreeId(), which is under updateFunctionComponent()
and mountIndeterminateComponent().
As mentioned in how does React traverse Fiber tree,
beginWork() is when we enter a fiber node.
From above code, we see that pushTreeId() is called with following info
- current fiber
- size of siblings(including itself)
- its
indexposition
One thing I need to point it out is that pushTreeId() is called after renderWithHooks(),
meaning pushTreeId() and getTreeId() happens inside of renderWithHooks(), which means
pushTreeId() actually pushes the info for next useId() call, not current one.
Now let’s dive into the core of useId().
Notice that a leading 1 is added to the id
treeContextOverflow = overflow;} else {// Normal pathconst newBits = slot << baseLength;const id = newBits | baseId;const overflow = baseOverflow;treeContextId = (1 << length) | id;----------------------------------Notice that a leading 1 is added to the id
treeContextOverflow = overflow;}}
Notice that a leading 1 is added to the id
treeContextOverflow = overflow;} else {// Normal pathconst newBits = slot << baseLength;const id = newBits | baseId;const overflow = baseOverflow;treeContextId = (1 << length) | id;----------------------------------Notice that a leading 1 is added to the id
treeContextOverflow = overflow;}}
Jeez, I have headaches every time I deal with bitwise operations, we can look at the normal path first.
js
js
slot is the position of fiber among its siblings, << shifts it forward, basically meaning multiple,
| baseId means addition.
Take an example in base 10 number system, it means id = slot * (10 ** baseLength) + baseId,
aka putting the slot to the left of the baseId.
Well here we are in binary world, so if baseId is 101, slot is 11, then the result is 11101.
Now for the other branch of if (length > 30), it is some improvement because the id could be too big exceeding 32 bits which
bitwise operations could not handle, so it split the id into smaller chunks. Recall in mountId() that toString(32) is called to generate
real ids, the lower bits could actually be processed and cached in treeContextOverflow.
This is why in mountId() we see the formula of id.toString(32) + overflow, since overflow is already converted to string.
It should be easy to understand why using an overflow chunk is working, because toString() transform number into another radix, but still higher bits are on the left, so once 5 bits could be converted into one character, it won’t change.
js
js
The idStack is a structure to holds info for the path to current fiber node. It is quite common in React source code,
we’ve already covered similar approach in how does Context work internally in React.
Explanation with example ids
We can grab the data from ReactDOMUseId-test.js to see some real ids.
DivWithId is a component that renders a div with id of the position part of useId(), keep in mind that
the ids on div in snippets below are the binary form of the internal data, useId() returns more complex string that contains the base-32 form
jsx
jsx
→
jsx
jsx
The initial id is empty bit - 0.
jsx
jsx
→
jsx
jsx
The first DivWithId has no siblings, so its position is not critical.
But in order to differentiate with the element inside, an extra bit is added every time an id is created.
So 1 is added to empty, which is 1.
And so it is obvious, if we have another layer of single DivWithId, it should be 11.
jsx
jsx
→
jsx
jsx
Ok let’s take a look at the cases of multiple children.
jsx
jsx
→
js
js
As mentioned in original PR, if there are multiple children things are a bit different.
For the first DivWithId, it is not 0 any longer, because it has siblings. Its position is 1 in 2 bits - '01', the leading zero is non-important in number system,
so after being added to the initial empty id, the final id is 1.
For the second DivWithId, its position is 2 - 10, so still 10 after being added to empty id.
jsx
jsx
→
jsx
jsx
For the first newly added DivWithId, it has no sibling.
As we said once id is generated, an extra bit will be added for the future ids inside, so 1 is added to 01,
which results in 101.
DivWithId. Now, how about the tree below?
jsx
jsx
Now the position of 101 in previous example has siblings, so its position 01 is going to be added to 101,
and its sibling has 10 added to 101.
jsx
jsx
Interesting.
Summary
We didn’t touch the actual id generation code, it costs too much of my brain with little benefit. With above examples of real ids, I think it is good enough to end this episode.
Just keep in mind that useId() generates unique ids based on its position on the fiber tree.

Want to know more about how React works internally?
Check out my series - React Internals Deep Dive!